[TOC]
本文是把《Kubernetes In Action》读薄的摘抄或转述,仅供参考。系统学习请阅读原书。
k8s的命令繁多,熟练使用它们提高工作效率和理解k8s设计思想同等重要,每章最后总结了该章涉及的命令。

7 ConfigMap 和 Secret :配置应用程序 195
7.1 配置容器化应用程序 195
因为pod的设计理念是无状态的,所以需要提供一种方式让pod中的应用可以读取到相应的配置文件。configMap就提供了一个集群级别的服务,让pod根据需求读取相应的配置(配置信息本质上是KV,不过可以以多种方式挂载)。
或者,pod的启动需要拉取registry的镜像,而registry可能会有授权认证,这时候就需要pod有认证信息,但是又不能直接将认证信息写进pod的配置(不然就所有的人都能看到了),所以最好能有一种等pod启动后再加载的相对安全的方式,这就是secret了。
使用configMap和secret的优点在于,配置可以动态的变化,而且容器完全不会感知到configMap和secret的存在,而是通过文件挂载等方式直接读取,不需要和configMap等直接交互。
7.2 向容器传递命令行参数 196
7.2.1 在 Docker 中定义命令与参数 196
容器中运行的完整指令由两部分组成:命令与参数。
Dockerfile中的两种指令分别定义命令与参数这两个部分:
- ENTRYPOINT 定义容器启动时被调用的可执行程序。
- CMD 指定传递给 ENTRYPOINT 的参数。
尽管可以直接使用CMD指令指定镜像运行时想要执行的命令,正确的做法依旧是借助ENTRYPOINT指令,仅仅用 CMD 指定所需的默认参数。镜像中定义的CMD可以被覆盖,而ENTRYPOINT无法被覆盖。
上述两条指令均支持以下两种形式:
- shell 形式:如 ENTRYPOINT node app . js。
- exec 形式:如 ENTRYPOINT ["node","app . js"]。
两者的区别在于指定的命令是否是在shell中被调用。
采用shell形式,PID 1是shell进程而非node进程,node进程于shell中启动。shell进程往往是多余的。所以通常可以直接采用exec形式的ENTRYPOINT指令。
7.2.2 在 Kubernetes 中覆盖命令和参数 199
1 | kind: pod |
Docker的ENTRYPOINT对应k8s的command,描述容器中运行的可执行文件。
Docker的CMD对应k8s的args,描述传给可执行文件的参数。
1 | apiVersion: v1 |
少量参数值的设置可以使用数组表示。多参数值情况下可以采用如下标记:
1 | args: |
7.3 为容器设置环境变量 200
7.3.1 在容器定义中指定环境变量 201
1 | spec: |
7.3.2 在环境变量值中引用其他环境变量 201
1 | env: |
7.3.3 了解硬编码环境变量的不足之处 202
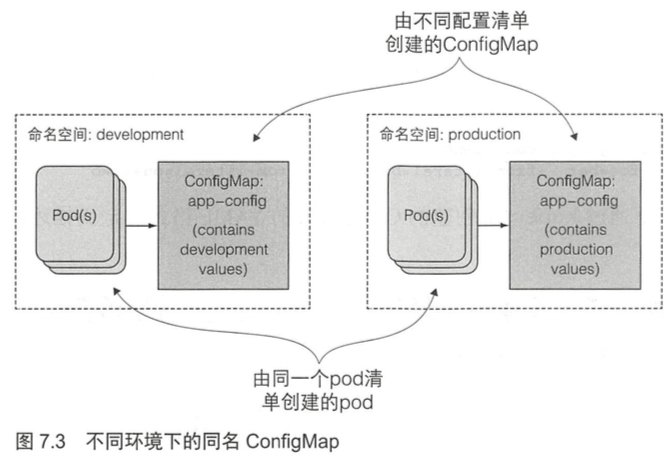
pod定义硬编码意味着需要有效区分生产和开发环境的pod定义。如果想在多个环境中能复用pod的定义,需要将配置从pod定义中解耦出来。——可以通过ConfigMap的资源对象完成解耦。
7.4 利用 ConfigMap 解耦配置 202
7.4.1 ConfigMap 介绍 202
k8s允许将配置选项分离到单独的资源对象ConfigMap中,本质上就是一个键/值对映射。
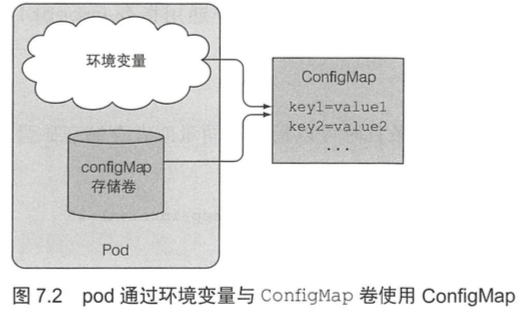
7.4.2 创建 ConfigMap 203
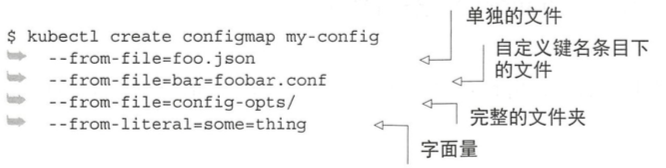
configMap创建自多种选项:完整文件夹、单独文件、自定义键名的条目下的文件(替代文件名作键名)以及字面量。
多种形式创建 configMap:
7.4.3 给容器传递 ConfigMap 条目作为环境变量 206
1 | spec: |
如果pod中引用了不存在的configMap会导致pod启动失败。如果稍后创建了该configMap后,pod就会自动启动。
7.4.4 一次性传递 ConfigMap 的所有条目作为环境变量 208
可以通过envFrom属性字段将所有条目暴露作为环境变量。
1 | spec: |
configMap里的名字必须符合环境变量格式才能被转为环境变量。k8s不会主动转换键名(例如不会将破折号转换为下画线)。如果configMap的某键名格式不正确,创建环境变量时会忽略对应的条目(忽略时不会发出事件通知)。
7.4.5 传递 ConfigMap 条目作为命令行参数 209
在字段pod.spec.containers.args中无法直接引用configMap的条目,但是可以利用configMap条目初始化某个环境变量,然后再在参数字段中引用该环境变量,形如 “$ENV_VAR”。
1 | spec: |
7.4.6 使用 configMap 卷将条目暴露为文件 210
configMap卷会将configMap中的每个条目均暴露成一个文件。key 为文件名,value 为文件内容。运行在容器中的进程可通过读取文件内容获得对应的条目值,所以可以用configMap来保存配置文件。
volume声明可以直接声明configMap,将configMap条目作为容器卷中的文件。
1 | spec: |
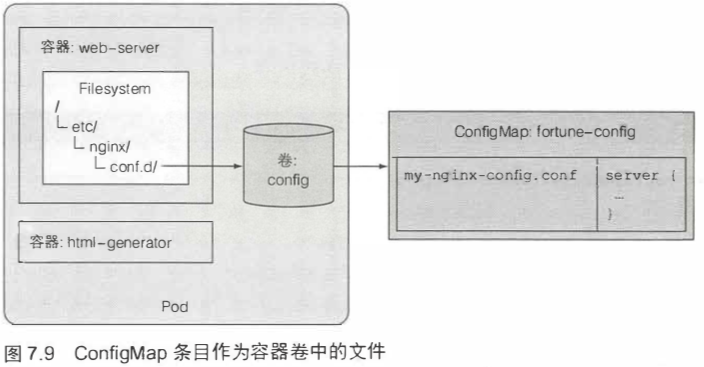
挂载任意一种卷时均可以使用subPath属性。可以选择挂载部分卷而不是挂载完整的卷。
1 | spec: |
configMap卷中所有文件的权限默认被设置为644,可以通过卷规则定义中的defaultMode属性改变默认权限。
1 | volume: |
7.4.7 更新应用配置且不重启应用程序 216
将configMap暴露为卷可以达到配置热更新的效果,无须重新创建pod或者重启容器。
如果挂载的是容器中的单个文件而不是完整的卷,configMap更新之后对应的文件不会被更新。 热更新只能运用于挂载整个文件夹。
7.5 使用 Secret 给容器传递敏感数据 218
7.5.1 介绍 Secret 218
secret和configMap最大的区别在于,secrets用于保存敏感的数据。
secret的数据都不会被写入磁盘,而是挂载在内存盘中。
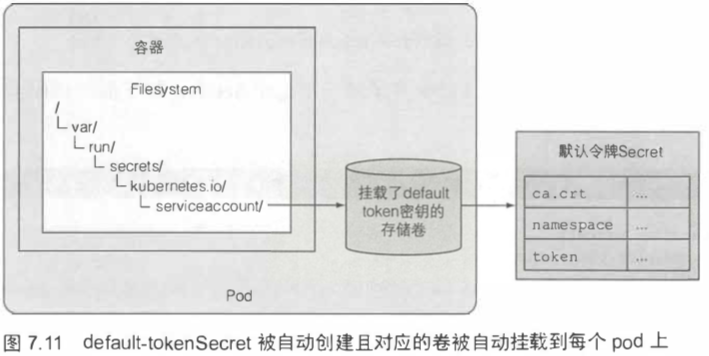
7.5.2 默认令牌 Secret 介绍 218
default-tokenSecret会被自动创建且对应的卷被自动挂载到每个pod上。
7.5.3 创建 Secret 220
与创建ConfigMap的过程类似。用kubectl create secret创建secret。
7.5.4 对比 ConfigMap 与 Secret 221
Secret条目的内容会被以Base64格式编码,而configMap直接以纯文本展示。采用Base64的原因在于,secret的条目可以涵盖二进制数据。
Secret的大小限于1MB。
k8s允许通过Secret的stringData字段设置条目的纯文本值。
1 | kind: Secret |
7.5.5 在 pod 中使用 Secret 222
挂载fortune-secret至pod。
1 | apiVersion: v1 |
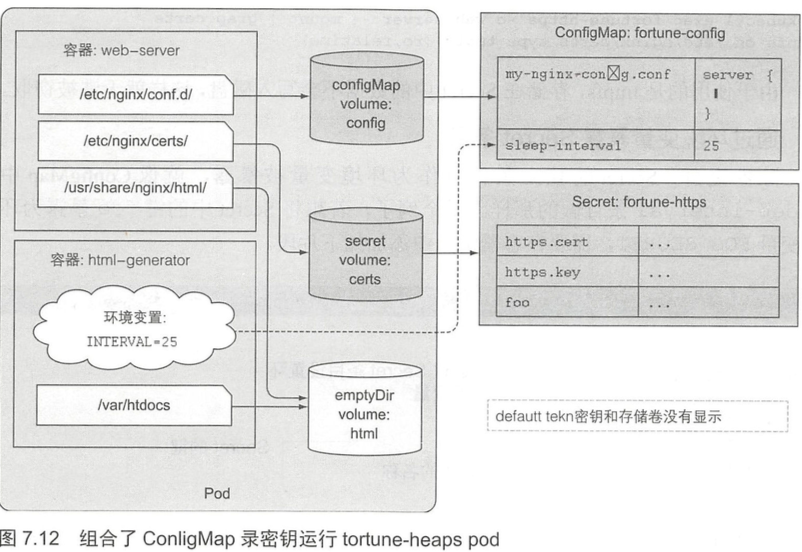
由于挂载时使用的是tmpfs,存储在Secret中的数据不会写入磁盘。
k8s允许通过环境变量暴露Secret,然而此特性的使用往往不是一个好主意。应用程序通常会在错误报告时转储环境变量,或者是启动时打印在应用日志中,无意中暴露了Secret信息。另外,子进程会继承父进程的所有环境变量,如果是通过第三方二进制程序启动应用,你并不知道它使用敏感数据做了什么。提示由于敏感数据可能在无意中被暴露,通过环境变量暴露Secret给容器之前请再三思考。为了确保安全性,请始终采用secret卷的方式暴露Secret。
7.6 本章的k8s命令 228
1 | ########## ConfigMap ########## |
8 从应用访问 pod 元数据以及其他资源 229
8.1 通过 Downward API 传递元数据 229
有时候,容器里的应用会需要获取到pod的metadata,或者node的一些信息,举几个例子来说:
- 应用希望获取到podmetadata中设置的labels。
- 应用需要调用主机上的一些端口(如daemonset),所以需要获取到主机的IP。
DownwardAPI允许我们通过环境变量或者文件(在downwardAPI卷中)的传递pod和node的元数据。
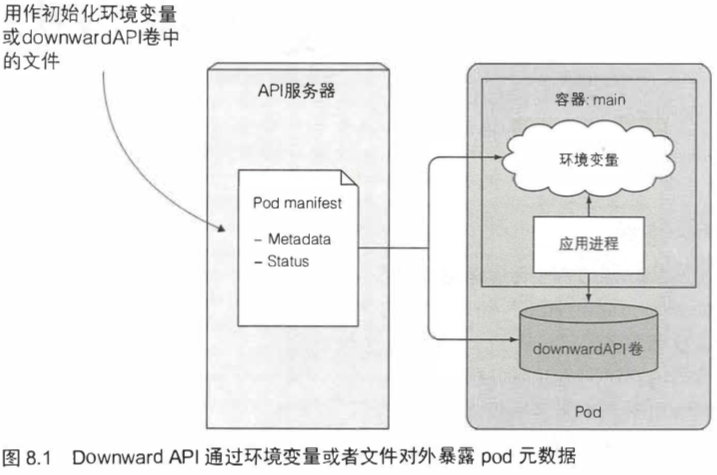
和configMap和secret类似,downwardAPI也是以volume的形式挂载。
8.1.1 了解可用的元数据 230
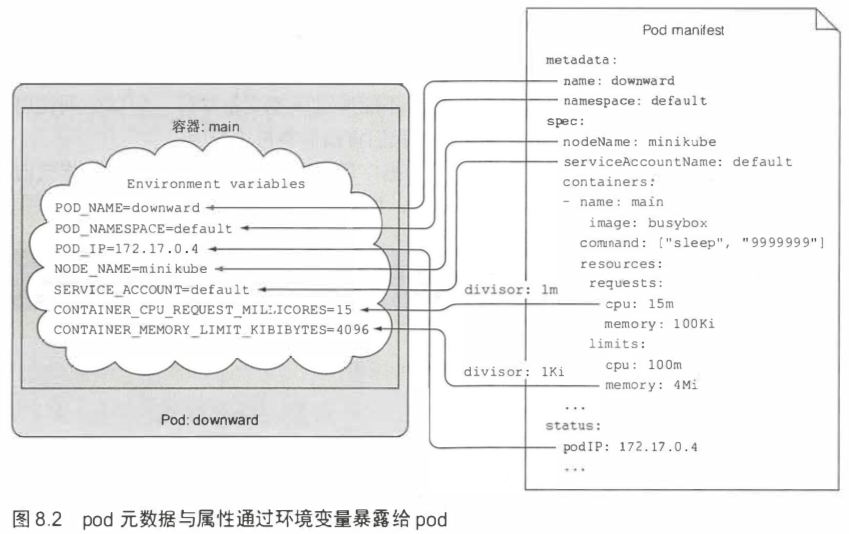
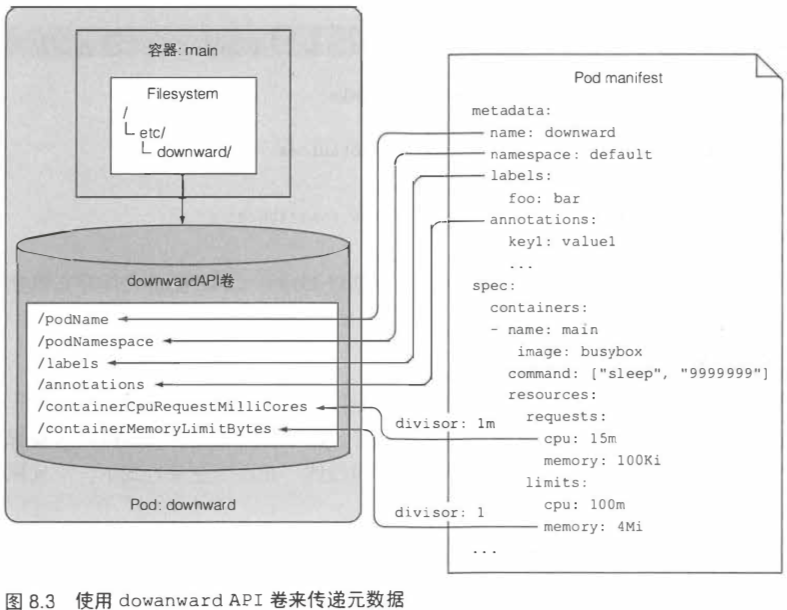
Downward API 可以给在pod 中运行的进程暴露pod的元数据。目前我们可以给容器传递以下数据:
- pod 的名称
- pod 的IP
- pod 所在的命名空间
- pod 运行节点的名称
- pod 运行所归属的服务账户的名称
- 每个容器请求的 CPU 和内存的使用量
- 每个容器可以使用的 CPU 和内存的限制
- pod 的标签
- pod 的注解
8.1.2 通过环境变量暴露元数据 231
1 | spec: |
获取资源用量的字段是resourceFieldRef。
对于暴露资源请求和使用限制的环境变量,我们会设定一个基数单位(divisor)。 实际的资源请求值和限制值除以这个基数单位,所得的结果通过环境变量暴露出去。
8.1.3 通过 downwardAPI 卷来传递元数据 234
如果更倾向于使用文件的方式而不是环境变量的方式暴露元数据,可以定义一个downwardAPI卷并挂载到容器中。
可以在pod运行时修改标签和注解。当标签和注解被修改后,k8s会更新存有相关信息的文件, 从而使pod可以获取最新的数据。这也解释了为什么不要通过环境变量的方式暴露标签和注解,在环境变量方式下,一旦标签和注解被修改,环境变量不会被动态更新。
1 | apiVersion: v1 |
8.2 与 Kubernetes API 服务器交互 237
downwardAPI的问题在于,只能暴露当前pod和当前节点的信息,如果我们需要获取集群中的其他信息,就需要去和APIServer交互了。
8.2.1 探究 Kubernetes REST API 238
在本地运行kubectl proxy,就会在127.0.0.1:8001开启一个代理端口。通过该代理就可以直接和APIServer交互(已经做好了所有的认证凭证等)。
8.2.2 从 pod 内部与 API 服务器进行交互 242
集群内的apiserver地址:https://kubernetes。
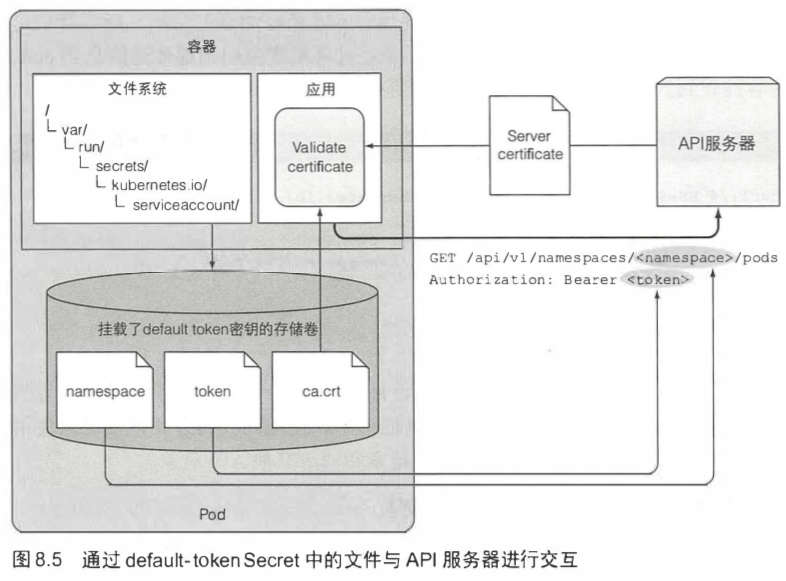
一个名为defalut-token-xyz的Secret被自动创建,并挂载到每个容器的/var/run/secrets/kubernetes.io/serviceaccount目录下,包含apiserver的ca和token。
8.2.3 通过 ambassador 容器简化与 API 服务器的交互 248
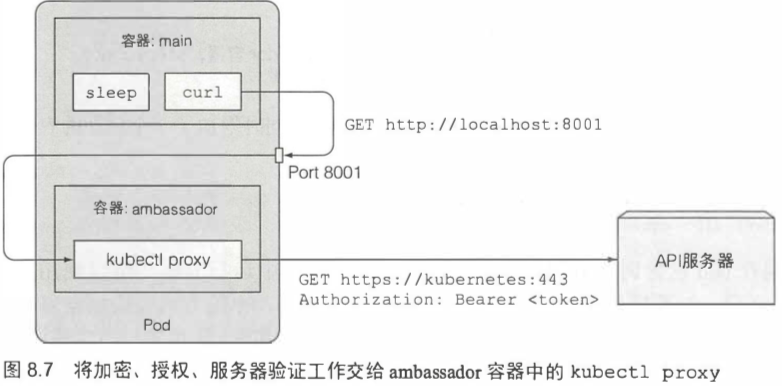
上述方法中,与APIServer交互需要手动处理ca和token。
有一个更简单的方式,在pod里启动一个sidecar容器,这个容器就负责运行kubectl proxy,然后主容器通过proxy端口和APIServer交互。
8.2.4 使用客户端库与 API 服务器交互 251
k8s API客户端库
- golang client - https://github.com/kubernetes/client-go
- python client - https://github.com/kubernetes-incubator/client-python
8.3 本章的k8s命令 253
1 | ########## downwardAPI ########## |
9 Deployment: 声明式地升级应用 255
9.1 更新运行在 pod 内的应用程序 256
9.1.1 删除旧版本 pod,使用新版本 pod 替换 257
Deployment是用户需要关心的负责管理pod的最小单位,在deployment的配置文件里可以直接一次性地配置pod和replicaset。使用deployment不但可以简单的迅速启动容器,还提供了非常方便的滚动升级的方法。
9.1.2 先创建新 pod 再删除旧版本 pod 257
手动执行滚动升级的方法繁琐,不建议。
9.2 使用 ReplicationController 实现自动的滚动升级 259
9.2.1 运行第一个版本的应用 259
1 | apiVersion: v1 |
9.2.2 使用 kubectl 来执行滚动式升级 261
如果使用同样的tag推送更新镜像,需要将容器的
imagePullPolicy属性设置为Always。当然最好使用一个新的tag来更新镜像。
可以用kubectl rolling-update来滚动升级rc,不过因为有deployment,所以rc已经不再使用了。在升级过程中,service将请求同时切换到新旧版本的pod。
9.2.3 为什么 kubectl rolling-update 已经过时 265
- 如果kubectl这个客户端在执行升级时失去了网络连接,升级进程将会中断。pod和rc最终会处于中间状态。
- k8s的理念是通过不断地收敛达到期望的系统状态。直接使用期望副本数来伸缩pod而不是手动地删除一个pod或者添加一个pod。只要在pod定义中更改所期望的镜像tag,并让k8s用运行新镜像的pod替换旧的pod。正是这一点推动了Deployment的新资源的引入。目前k8s中部署应用程序首选这种方式。
9.3 使用 Deployment 声明式地升级应用 266
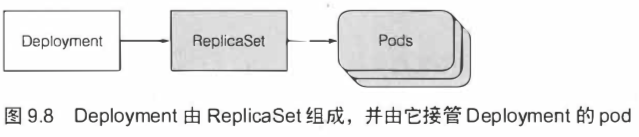
rc和rs已经能保证一组pod实例的正常云进行了,为什么要在rc或rs之上再引入另一个对象?
在升级应用程序时,需要引入一个额外的rc,并协调两个controller,使它们再根据彼此不断地修改,而不会造成干扰。所以需要Deployment资源来协调。
9.3.1 创建一个 Deployment 267
1 | apiVersion: apps/v1 |
Deployment可以同时管理多个版本的pod,所以在命名时不需要指定应用的版本号。
通过kubectl create -f xxxx-deployment.yml --record创建一个Deployment。在创建时使用了--record选项,这个选项会记录历史版本号。

现在由Deployment创建的三个pod名称中均包含一个额外的数字。这个数字对应Deployment和ReplicaSet中的pod模板的哈希值。
ReplicaSet的名称中也包含了其pod模板的哈希值。之后的篇幅也会介绍,Deployment会创建多个ReplicaSet,用来对应和管理一个版本的pod模板。像这样使用pod模板的哈希值,可以让Deployment始终对给定版本的pod模板创建相同的(或使用已有的)ReplicaSet。
9.3.2 升级 Deployment 269
只需修改Deployment资源中定义的pod模板,Kubernetes 会自动将实际的系统状态收敛为资源中定义的状态。
如何达到新的系统状态的过程是由Deployment的升级策略决定的,默认策略是执行滚动更新(策略名为 RollingUpdate)。 另一种策略为Recreate,它会一次性删除所有旧版本的pod,然后创建新的pod。
升级过程是由运行在k8s上的一个控制器处理和完成的(而不再是手动执行kubectl rolling-update), 只有通过修改deployment内的pod信息才会触发升级。
如果Deployment中的pod模板引用了一个configMap(或 Secret),那么更改configMap资源本身将不会触发升级操作。 如果真的需要修改应用程序的配置并想触发更新的话,可以通过创建一个新的configMap并修改pod模板引用新的configMap。
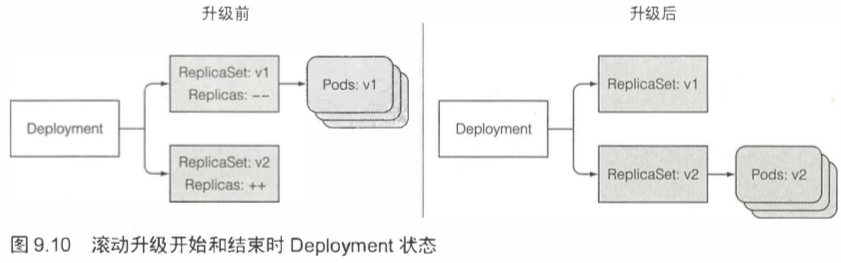
与rc类型,所有新的pod现在由心的rs管理。但是不同的是,旧的rs会被保留,而旧的rc会在滚动升级过程后被删除。
9.3.3 回滚 Deployment 273
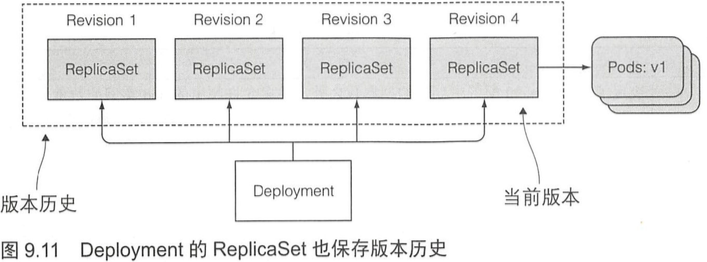
滚动升级成功后,老版本的 ReplicaSet 也不会被删掉,回滚操作可以回滚到任何一个历史版本。
旧版本的ReplicaSet过多会导致ReplicaSet列表过于混乱,可以通过指定Deployment的revisionHistoryLimit属性来限制历史版本数量。默认值是2,所以正常情况下在版本列表里只有当前版本和上一个版本(以及只保留了当前和上一个ReplicaSet),所有再早之前的ReplicaSet都会被删除。注意extensions/v1beta1版本的Deployment的revisionHistoryLimit没有值,在apps/v1beta2版本中,这个默认值是10。
9.3.4 控制滚动升级速率 276
在Deployment的滚动升级期间,有两个属性会决定一次替换多少个pod: maxSurge和maxUnavailable。默认都是25%。
1 | spec: |
9.3.5 暂停滚动升级 278
通过kubectl rollout pause/resume来手动控制滚动步骤。通过暂停滚动升级过程,只有一小部分客户端请求会切换到v4 pod,而大多数请求依然仍只会切换到v3 pod。 一旦确认新版本能够正常工作,就可以恢复滚动升级。
在滚动升级过程中,想要在一个确切的位置暂停滚动升级目前还无法做到,以后可能会有一种新的升级策略来自动完成上面的需求。但目前想要进行金丝雀发布的正确方式是, 使用两个不同的Deployment并同时调整它们对应的pod数量。
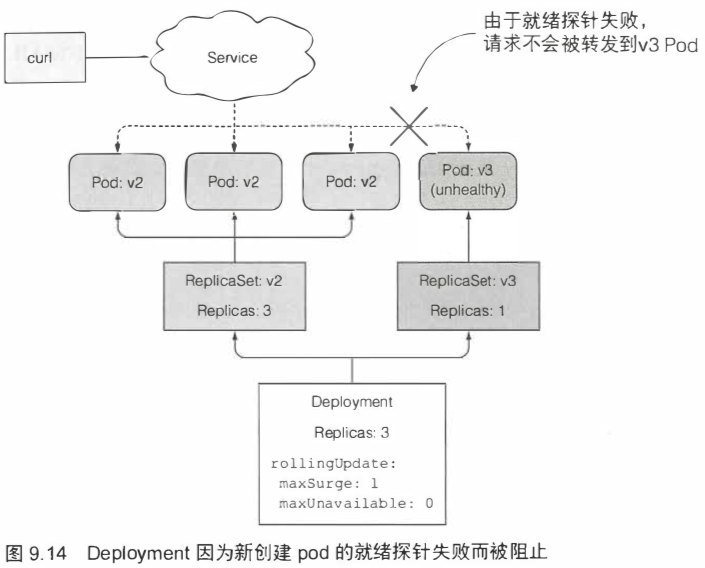
9.3.6 阻止出错版本的滚动升级 279
k8s可以设置多种就绪探针,来探测pod是否已经ready,可以接收svc的流量。
minReadySeconds属性指定新创建的pod至少要成功运行多久之后,才能将其视为可用。在pod可用之前,滚动升级的过程不会继续。
默认情况下,在10分钟内不能完成滚动升级的话,将被视为失败。如果运行kubectl describe deployment命令, 将会显示一条 ProgressDeadlineExceeded的记录。
如果只定义就绪探针没有正确设置minReadySeconds,一旦有一次就绪探针调用成功,便会认为新的pod已经处于可用状态。
1 | apiVersion: apps/v1beta1 |
9.4 本章的k8s命令 284
1 | ########## deployment ########## |
10 StatefulSet :部署有状态的多副本应用 285
10.1 复制有状态 pod 285
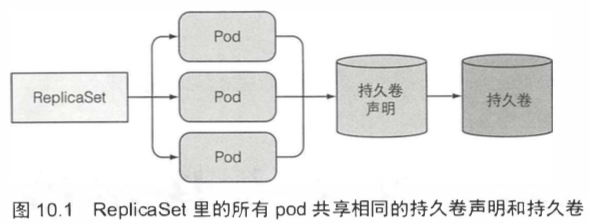
ReplicaSet通过一个pod模板创建多个pod副本。这些副本除了它们的名字和IP地址不同外,没有别的差异。
10.1.1 运行每个实例都有单独存储的多副本 286
一个比较取巧的做法是:所有pod共享同一数据卷,但是每个pod在数据卷中使用不同的数据目录。实现方法是让每个实例自动选择或创建一个别的实例还没有使用的数据目录。但是这种方法,需要实例之间互相协作,增加难度。
10.1.2 每个 pod 都提供稳定的标识 287
针对集群中的每个成员实例,都创建一个独立的service来提供稳定的网络地址。因为服务IP是固定的,可以在配置文件中指定集群成员对应的服务IP(而不是pod IP)。但这不是好的解决办法,因为pod无法知道它对应的service,不能在别的pod里通过服务IP自行注册。
10.2 了解 Statefulset 289
10.2.1 对比 Statefulset 和 ReplicaSet 289
与ReplicaSet不同的是,Statefulset创建的pod副本并不是完全一样的。每个pod都可以拥有一组独立的数据卷(持久化状态)而有所区别。
10.2.2 提供稳定的网络标识 290
一个Statefulset创建的每个pod都有一个从零开始的顺序索引,这个会体现在pod的名称和主机名上,同样还会体现在pod对应的固定存储上。这些pod的名称则是可预知的,因为它是由Statefulset的名称加该实例的顺序索引值组成的。
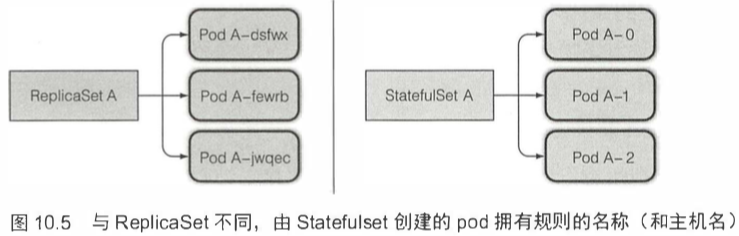
一个StatefulSet通常要求你创建一个用来记录每个pod网络标记的headless Service。通过这个Service,每个pod将拥有独立的DNS记录,这样集群里它的伙伴或者客户端可以通过主机名方便地找到它。比如说,一个属于default命名空间,名为foo的控制服务,它的一个pod名称为A-0,那么可以通过下面的完整域名来访问它a-0.foo.default.svc.cluster.local。而在ReplicaSet中这样是行不通的。
另外,也可以通过 DNS 服务,查找域名foo.default.svc.cluster.local对应的所有SRV记录, 获取一个Statefulset中所有pod的名称。
调度时,Statefulset使用标识完全一致的新的pod替换,ReplicaSet则是使用一个不相干的新的pod替换。缩容一个Statefulset将会最先删除最高索引值的实例。
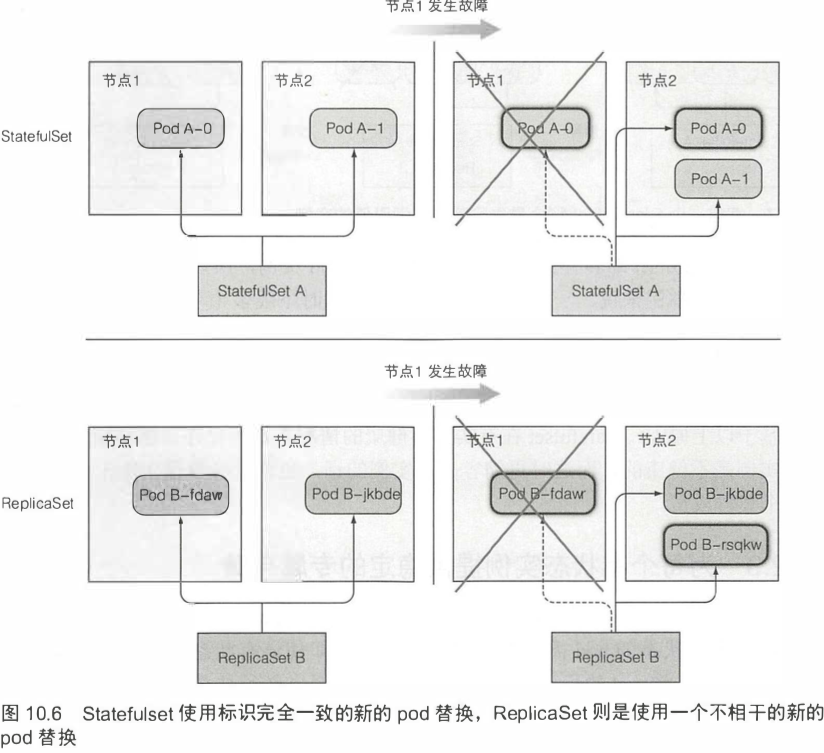
10.2.3 为每个有状态实例提供稳定的专属存储 292
Statefulset在有实例不健康的情况下是不允许做缩容操作的。statefulset会为每一个pod绑定一个不同的固定的pvc,而且该pvc会在pod删除后依然保留,pvc只能手动删除。
因为缩容Statefulset时会保留持久卷声明,所以在随后的扩容操作中,新的pod实例会使用绑定在持久卷上的相同声明和其上的数据。当你因为误操作而缩容一个Statefulset后,可以做一次扩容来弥补自己的过失,新的pod实例会运行到与之前完全一致的状态(名字也是一样的)。
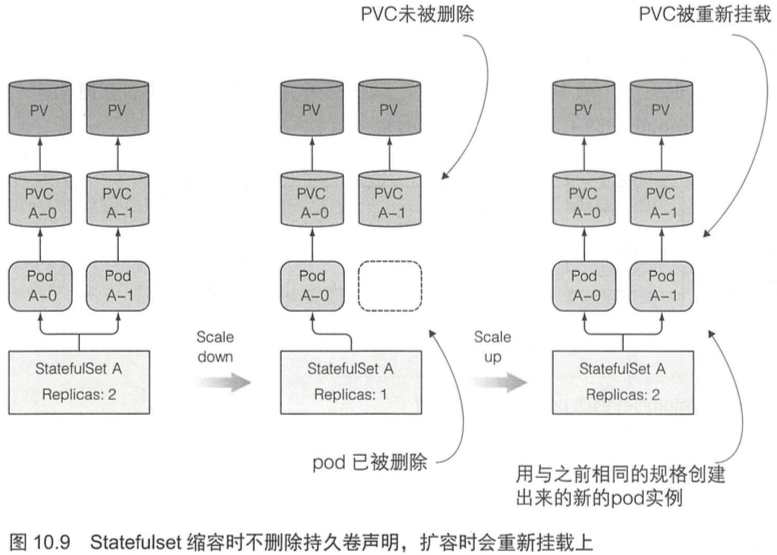
10.2.4 Statefulset 的保障 294
Statefulset拥有稳定的标记和独立的存储。通常来说,无状态的pod是可以替代的,有状态的pod则不行。k8s必须保证两个拥有相同标记和绑定相同持久卷声明的有状态的pod实例不能同时运行。一个Statefulset必须保证有状态的pod实例的at-most-one语义。一个Statefulset必须在准确确认一个pod不再运行后,才会去创建它的替换pod。
10.3 使用 Statefulset 295
10.3.1 创建应用和容器镜像 295
使用kubia应用作为基础镜像,让每个pod实例都能用来存储和接收一个数据项。
10.3.2 通过 Statefulset 部署应用 296
为了部署应用,需要创建两个(或三个)不同类型的对象:
- 存储你数据文件的持久卷(当集群不支持持久卷的动态供应时,需要手动创建)
- Statefulset必需的一个控制Service
- Statefulset本身
在部署statefulSet前,需要先创建一个用于在有状态的pod之间提供网络标识的headless service。
1 | apiVersion: v1 |
第二个pod会在第一个pod运行并且处于就绪状态后创建。Statefulset这样的行为是因为:状态明确的集群应用对同时有两个集群成员启动引起的竞争情况是非常敏感的。所以依次启动每个成员是比较安全可靠的。
10.3.3 使用你的 pod 301
API服务器的一个很有用的功能就是通过代理直接连接到指定的pod。如果想请求当前的 kubia-0 pod,可以通过如下 URL:<apiServerHost>:<port>/api/v1/namespaces/default/pods/kubia-0/proxy/<path>。
通过 kubectl proxy 访问服务,都会经过两个代理的两次跳转。
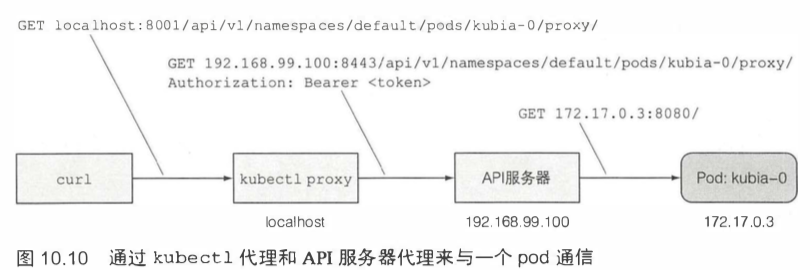
statefulSet的pod在重启后也有可能会被调度到不同的节点上,但是会保留它的存储卷和主机名。
10.4 在 Statefulset 中发现伙伴节点 305
10.4.1 通过 DNS 实现伙伴间彼此发现 306
k8s通过一个headless service创建SRV记录来指向pod的主机名。创建svc的目的就是在dns中生成srv记录,这一记录会返回与该svc关联的所有的pods。
10.4.2 更新 Statefulset 308
可以使用kubectl edit statefulset来更新stateful的配置。
Statefulset更像ReplicaSet,而不是Deployment,所以在模板被修改后,它们不会重启更新。 需要手动删除这些副本,然后Statefulset会依据新的模板重新调度启动它们。不会主动删除旧pod,等手动删除后,才会自动创建新pod。
10.4.3 尝试集群数据存储 309
当一个客户端请求到达集群中的任意一个节点后,它会发现它的所有伙伴节点,然后通过它们收集数据,然后把收集到的所有数据返回给客户端。
10.5 了解 Statefulset 如何处理节点失效 310
10.5.1 模拟一个节点的网络断开 310
Statefulset要保证不会有两个拥有相同标记和存储的pod同时运行,当一个节点似乎失效时,Statefulset在明确知道一个pod不再运行之前,它不能或者不应该创建一个替换pod, 保证at-most-one。
只有当集群的管理者告诉它这些信息的时候,它才能明确知道。为了做到这一点,管理者需要删除这个pod,或者删除整个节点。
若该节点过段时间正常连通,并且重新汇报它上面的pod状态,那这个pod就会重新被标记为 Runing。 但如果这个pod的未知状态持续几分钟后(这个时间是可以配置的),这个pod就会自动从节点上驱逐。 不过所谓的”驱逐”也只是k8s会试图删除该 pod,但是由于节点不可达,所以节点状态会停留在Terminating。
10.5.2 手动删除 pod 312
除非确认节点不再运行或者不会再可以访问,否则不要强制删除有状态的pod。
10.6 本章的k8s命令 313
1 | ########## Statefulset ########## |

